Fundamentos, playbook de implementação e como a IA redefine a gestão de dados nas organizações
triggo.ai · Data & AI Product Management
Parte I
I
Fundamentos e Visão Moderna de Data Product
O que é um produto de dados, por que ele importa e como os domínios de negócio são a base de tudo — uma visão conceitual e estratégica para organizações que querem gerar valor real com dados.
Capítulo 1.1
Visão Moderna de Data Product & AI
Na triggo.ai, vemos um padrão que se repete com frequência nos projetos com clientes: as discussões sobre produtos de dados partem diretamente para questões de segunda camada — qual arquitetura adotar, se o time precisa de um data mesh ou de uma plataforma consolidada, se determinado dataset se enquadra ou não na definição de produto. São questões legítimas, mas que carregam um pressuposto implícito problemático: o de que o objetivo central é ter produtos de dados.
Não é. O objetivo é o que uma organização consegue realizar quando seus produtos de dados estão funcionando de verdade. Um Data Product bem construído é ponte, não destino — é a infraestrutura que converte informação em capacidade de agir. Organizações que o tratam como troféu constroem portfólios técnicos sofisticados que impressionam em apresentações e se tornam obsoletos quando o patrocinador executivo muda de cadeira. As que o tratam como alavanca constroem algo diferente: um ativo que se valoriza com o tempo, onde cada produto entregue facilita e acelera o próximo.
"Dados não geram valor por existirem. Geram valor quando chegam à mão certa, no momento certo, na forma certa — e mudam o que alguém consegue fazer."
— triggo.ai, baseado em conceitos de Amy Raygada
Os quatro resultados que um Data Product realmente entrega
Quando um produto de dados está genuinamente em uso — quando equipes o buscam espontaneamente, tomam decisões com base nele e passariam a sentir sua falta caso deixasse de existir — ele produz quatro efeitos concretos e simultâneos na organização.
🎯
Rupturas de Capacidade Decisória
Não melhorias marginais em análises que já existiam — mas saltos qualitativos no que a organização consegue fazer. Um time de suprimentos que passou anos operando sem visibilidade consolidada de risco de fornecedores agora consegue agir preventivamente. Uma equipe de saúde que reagia a readmissões passou a antecipar risco 24 horas antes da alta. Essas não são melhorias de processo: são novas capacidades que não existiam antes do produto.
🤝
Confiança que se Acumula
O ativo mais escasso em qualquer time de dados. Usuários de negócio carregam um histórico de decepções: números que contradiziam outros números na mesma reunião, plataformas adotadas e abandonadas, dashboards que ninguém mais abria. Um produto com contratos de qualidade explícitos, SLOs monitorados e ownership claro quebra esse ciclo. E a confiança construída no primeiro produto não precisa ser reconquistada do zero no segundo — ela se transfere.
⚡
Velocidade de Resposta ao Negócio
O modelo centralizado de dados — onde toda demanda analítica passa por uma fila única gerenciada por um time especializado — cria um gargalo que a maioria das lideranças subestima. Cada hora que uma decisão estratégica aguarda análise é uma hora de vantagem competitiva que não foi capturada. Data Products distribuídos, com interfaces de consumo estáveis e dados confiáveis, eliminam esse intermediário e encurtam o ciclo da pergunta à ação.
🚀
Fundação para o Próximo Salto
A dimensão menos discutida em estudos de caso e a de maior retorno no longo prazo. Dados organizados, documentados e governados como produto se tornam insumo direto para modelos de IA. Produtos analíticos maduros viram base para sistemas de decisão automatizados. Times que aprenderam a construir com adoção real desenvolvem um instinto de produto que se aplica a tudo que criam depois. O valor composto de um ecossistema de Data Products supera em muito a soma de seus produtos individuais.
Dados fragmentados não são um problema de IA — são um problema de produto
Há um diagnóstico que se tornou incômodamente familiar no setor: a maioria dos projetos de IA corporativa não falha por limitação dos modelos. Falha porque os dados que alimentam esses modelos estão fragmentados, mal documentados e sem governança consistente. Quando um sistema de IA opera sobre essa base, ele replica e amplifica os problemas existentes — não os resolve.
O que a adoção em larga escala de IA revelou não é um problema novo. Qualidade de dados é um desafio que o setor conhece há décadas. O que mudou foi a escala das consequências. Num ambiente tradicional de relatórios, um dado ruim gera um número errado num relatório mensal — alguém percebe, uma correção é emitida, o impacto é localizado. Num sistema de IA em produção, o mesmo dado ruim gera decisões erradas em tempo real, de forma automatizada, atingindo centenas ou milhares de pessoas antes que qualquer processo de monitoramento convencional consiga detectar o desvio. A recusa de um crédito baseada em informação incompleta. Uma triagem clínica distorcida por um dataset de treinamento enviesado. Um sistema antifraude que falha sistematicamente para um segmento inteiro de clientes.
A sequência que não pode ser invertida
Organizações que constroem IA confiável não começam escolhendo o modelo — começam pela camada que torna qualquer modelo confiável: os dados. Quando o dado é tratado como produto, a qualidade passa de checagem final para requisito de entrada. Cada pipeline carrega seus próprios contratos. Cada domínio responde pela integridade do que produz. Os dados que alimentam sistemas de IA podem ser rastreados, auditados e controlados de forma que o comportamento do sistema seja compreensível e defensável. Sem essa fundação, escalar IA significa escalar também os erros que ela vai cometer.
O papel do produto de dados não é substituir quem decide — é melhorar como se decide
Parte do debate contemporâneo sobre IA assume que o julgamento humano é uma etapa a ser eliminada do processo decisório. Para um conjunto específico de decisões — alto volume, critérios bem definidos, baixo risco individual —, essa premissa faz sentido. Detecção de anomalias em transações financeiras, moderação automatizada de conteúdo, alertas preditivos em sistemas industriais com padrões de falha conhecidos: nesses casos, a automação entrega mais velocidade e consistência do que qualquer processo humano conseguiria.
Mas as decisões que mais definem o desempenho de uma organização — alocação de recursos, avaliação de riscos estratégicos, julgamentos que envolvem contexto, nuance e responsabilidade institucional — não são candidatas à automação. O julgamento humano nessas situações não é ineficiência. É o ponto central. A questão pertinente não é como removê-lo, mas como torná-lo melhor: mais fundamentado em evidências, mais consistente entre diferentes tomadores de decisão, mais rápido sem sacrificar rigor.
Um produto de dados bem concebido opera exatamente nesse espaço. Ele não substitui quem decide — reconfigura as condições sob as quais a decisão é tomada. Entrega o dado certo à pessoa certa no momento em que ela precisa, no formato que ela consegue processar. E quando o produto aponta para incerteza ou baixa confiança nos dados, ele sinaliza isso explicitamente — em vez de apresentar uma resposta com aparência de precisão que mascara limitações reais. Isso exige pensamento de produto, não apenas engenharia de dados: entender profundamente a pessoa que vai usar o sistema, as decisões que ela toma, o contexto em que opera e as consequências pelas quais responde.
A capacidade que se acumula a cada produto entregue
Existe uma diferença estrutural entre organizações que constroem produtos de dados de forma consistente e as que empilham projetos. As primeiras desenvolvem uma competência que se valoriza com o uso. As segundas acumulam complexidade sem acumular capacidade.
Times que praticaram pesquisa com usuários antes de desenvolver deixam de desperdiçar meses em soluções que ninguém pediu. Times que automatizaram governança e qualidade deixam de consumir energia de engenharia resolvendo crises recorrentes em produção. Times que demonstraram ROI mensurável param de disputar orçamento e começam a ser procurados por áreas de negócio que querem replicar o resultado. E lideranças que vivenciaram o retorno concreto de um investimento em produto de dados passam a tratar dados como ativo estratégico — não como linha de custo a ser contida.
Essa acumulação segue uma lógica composta: o primeiro produto que ganha a confiança dos usuários reduz o esforço de adoção do segundo. A primeira estrutura de governança que funciona sem atritar o time de desenvolvimento acelera a implementação de todas as seguintes. O primeiro estudo de caso com impacto financeiro documentado transforma a conversa orçamentária de forma permanente. A organização não apenas acumula produtos — desenvolve uma habilidade estrutural de transformar dados em valor que melhora a cada ciclo.
"A tecnologia é o material de construção. O pensamento de produto é a planta arquitetônica. E colocar o ser humano no centro do design é o que garante que o que se constrói seja forte o suficiente para sustentar o peso das decisões que precisam atravessá-lo."
— Amy Raygada, adaptado pela triggo.ai
Por isso, a pergunta estratégica que toda organização deveria fazer antes de qualquer decisão sobre plataforma, arquitetura ou modelo de IA é esta: o que queremos que nossas equipes consigam fazer — para o negócio e para as pessoas que servimos — que hoje não conseguem? Quando essa pergunta é respondida com honestidade e especificidade, ela define naturalmente quais produtos construir primeiro, quem envolver no processo, e o que vai contar como sucesso de uma forma que faz sentido tanto para a liderança quanto para quem opera na linha de frente.
O problema original
Capítulo 1.2
O Problema que Originou o Conceito
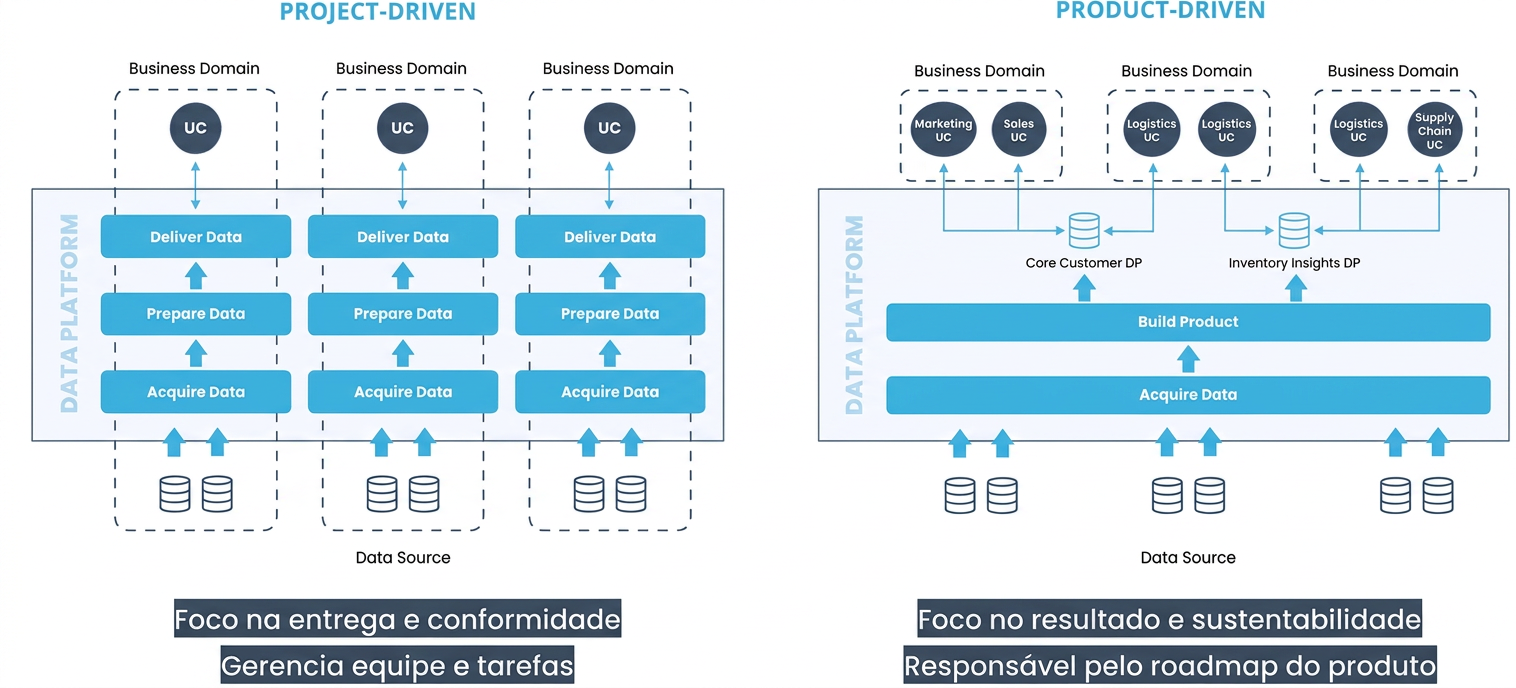
Durante décadas, as organizações trataram dados como subproduto das operações — armazenados em silos, duplicados em pipelines frágeis e entregues por times centrais sobrecarregados. O time de dados existia para responder chamados. Um stakeholder precisava de uma análise: abria um ticket, esperava dias, recebia uma resposta muito específica e raramente havia proatividade ou visão de valor contínuo.
Essa mentalidade orientada a serviço criou um paradoxo: quanto mais dados a organização acumulava, mais lento e opaco era o processo de transformá-los em decisão. E um segundo problema silencioso se instalava: a ausência de ownership claro dos dados. Ninguém sabia exatamente quem era responsável pela qualidade, pela evolução e pelo impacto de cada conjunto de dados.
"Equipes de dados orientadas a serviços geralmente acabam sendo construídas como departamentos com uma mentalidade de “enviar um chamado com uma pergunta, obter uma resposta muito específica”. Raramente gastam tempo sendo proativas."
— triggo.ai, Aula 2 — Fundamentos sobre Data Product
A virada conceitual começa quando se deixa de perguntar "onde estão nossos dados?" e passa-se a perguntar "quem é responsável por este dado, para quem ele serve e qual valor ele entrega?". Essa mudança de pergunta é a essência do Data Product. Não é uma mudança técnica — é uma mudança de mentalidade organizacional que tem implicações profundas na arquitetura, nos papéis e na cultura dos times de dados.
O que é um Data Product
Capítulo 1.3
Definição, Anatomia e Exemplos Práticos
A primeira definição formal foi de DJ Patil, ex-Chief Data Scientist dos EUA: um produto de dados é qualquer produto que facilita um objetivo final por meio do uso de dados. Essa definição intencional é ampla — inclui desde uma página personalizada de um e-commerce até um modelo de crédito ou um dashboard executivo.
No contexto de Data Mesh, Zhamak Dehghani aprofundou o conceito: Data Products são o "architecture quantum" — a menor unidade arquitetural que pode ser implantada e gerenciada de forma independente. Análogo a um microserviço na engenharia de software, mas voltado ao domínio do dado. Em seu livro Data Mesh: Delivering Data-Driven Value at Scale, Dehghani define que os Data Products são "the smallest unit of architecture that can be independently deployed and managed".
Na prática, um Data Product pode assumir múltiplas formas — desde que seja construído pensando no consumidor e no valor que entrega:
🗃️
Tabela, Schema ou View
Um modelo de dados publicado, como uma view materializada que une dados de clientes de diversas fontes (CRM, analytics, CSVs). É um Data Product se tiver owner, documentação e SLOs definidos — do contrário, é apenas uma tabela.
📊
Relatório ou Painel
Um dashboard Customer 360 que unifica vendas, marketing e serviço. É um Data Product se tiver consumidor definido, for certificado e tiver métricas de confiabilidade monitoradas continuamente.
🤖
Modelo de ML ou Métrica
Um modelo de churn ou análise de sentimento disponível como API ou função reutilizável. Atenção: o modelo em si não é o produto — o que você faz com os resultados do modelo pode se tornar um produto de IA.
🔌
API de Dados
Uma interface programática que expõe dados de um domínio com contrato explícito, versionamento e garantias de qualidade — o equivalente a uma API de software aplicada ao dado.
O critério decisivo
A partir do momento em que você leva em conta o que o consumidor quer e precisa — e constrói o dado pensando nessa necessidade — ele se torna um produto de dados. O que transforma tabelas, views e modelos em produto é a intenção de servir um consumidor, com qualidade, contexto e accountability explícitos.
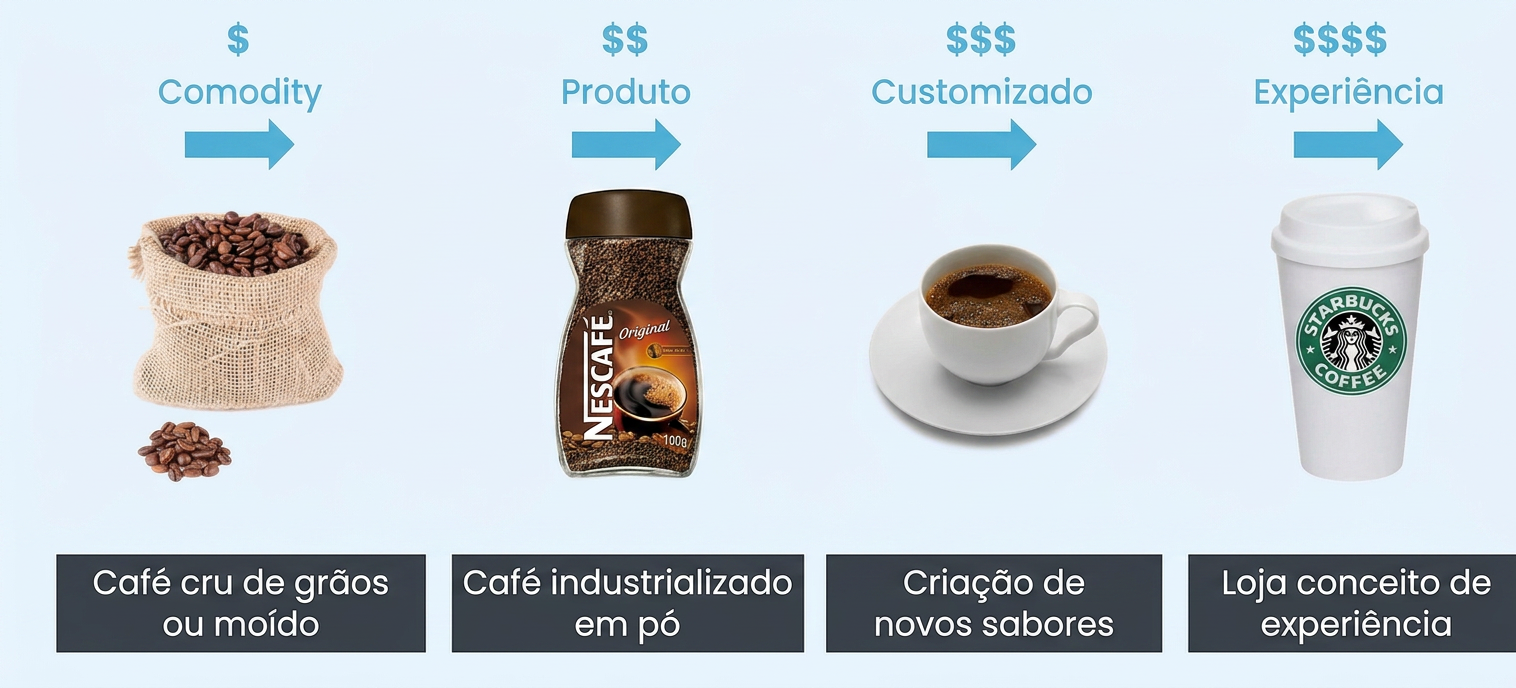
A escala de valor: de commodity a experiência
Uma analogia poderosa para entender os níveis de maturidade de um produto de dados: a cadeia de valor do café. O dado bruto, não estruturado ou não processado, é a matéria-prima — o grão de café, uma commodity com valor mínimo. Organizado e estruturado, torna-se um produto fácil de consumir. Com insights processados e prontos para uso, é um produto customizado. E quando a solução é personalizada para entregar valor exclusivo a um contexto específico de negócio, chega-se ao nível de experiência — diferenciado e de alto valor.
Organizações que operam apenas no nível de commodity entregam dados brutos sem contexto. As que chegam ao nível de experiência entregam produtos que antecipam a necessidade do consumidor e se integram ao fluxo de decisão. O objetivo de uma estratégia de Data Product é mover consistentemente a organização nessa escala — priorizando os domínios de maior impacto no negócio.
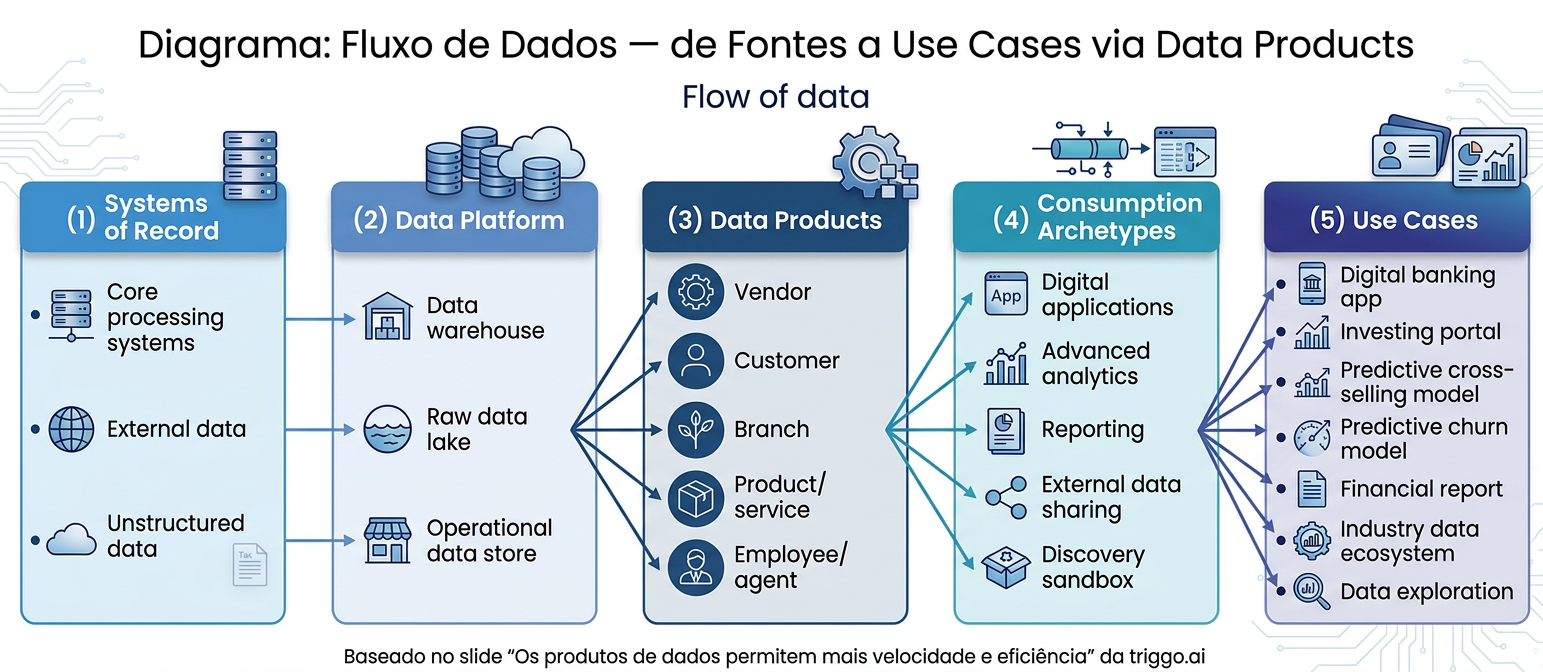
Os produtos de dados permitem mais velocidade e eficiência
A cadeia de valor de um produto de dados moderno segue um fluxo que começa nos sistemas de registro (core processing systems, external data, unstructured data), passa pela plataforma de dados (warehouse, data lake, operational data store), chega aos Data Products organizados por domínio (Vendor, Customer, Branch, Product/Service, Employee/Agent) e finalmente habilita os archetypes de consumo: aplicações digitais, analytics avançado, reporting, compartilhamento externo e exploração de dados.
Características essenciais
Capítulo 1.4
As Características Fundamentais de um Data Product
Zhamak Dehghani definiu as propriedades que um produto de dados deve ter para ser genuinamente útil em escala. Essas características não são opcionais — são o critério mínimo que separa um produto de dados de um simples artefato de dados:
Característica
O que significa na prática
Discoverable
Registrado em catálogo com metadados adequados. Se o produto não pode ser encontrado, não existe para quem poderia usá-lo. Um dos objetivos centrais é a reutilização — e isso requer descoberta. Catálogos de dados devem ser estendidos para incluir produtos de dados com todos seus atributos.
Addressable
Cada produto de dados tem um ponto de acesso único e estável (API, endpoint, URI). Consumidores sabem onde encontrá-lo e como acessá-lo de forma previsível e programática.
Trustworthy
Monitorado por SLOs que garantem precisão, frescor e completude. A perda de confiança na veracidade da informação é o maior inimigo da adoção. Não há maior problema para a adoção de produtos de dados do que a perda de confiança na veracidade da informação.
Self-Describing
Acompanhado de documentação, metadados e contexto de negócio suficientes para que qualquer consumidor compreenda o dado sem depender do time produtor.
Interoperable
Governado por padrões abertos que permitem integração com outros produtos de dados e sistemas, internos ou externos.
Secure
Controles de acesso dinâmicos que permitem que diferentes consumidores vejam diferentes resultados do mesmo produto, respeitando LGPD, HIPAA e demais regulações de privacidade.
Além dessas seis propriedades, há dois pilares operacionais igualmente críticos: Observability — capacidade de detectar automaticamente anomalias, mudanças de schema, dados fora de ordem e falhas de pipeline antes que cheguem ao consumidor — e Operations — uma linha de montagem DataOps que automatiza, testa e implanta produtos de forma contínua e confiável, reduzindo a dependência de habilidades escassas de engenharia de dados.
Data Product Management: a tríade conceitual
Para gerenciar produtos de dados com efetividade, a triggo.ai estrutura o escopo em três eixos integrados:
Conceito
Subdivisões
Descrição
Data
Data model, schema, metadata
A base estrutural: organização, tipagem, relacionamentos e informações sobre o dado em si.
Domain
Metrics, semantic, transformations, ML
O conhecimento de domínio embutido: métricas de negócio, significado dos dados, transformações aplicadas e modelos analíticos.
Access
Visualization, APIs, SQL, GUI, security
As formas pelas quais os consumidores interagem com o produto: interfaces visuais, APIs, SQL self-service e controles de segurança.
Domínios de dados
Capítulo 1.5
Domínios de Dados: A Unidade Organizacional que Tudo Sustenta
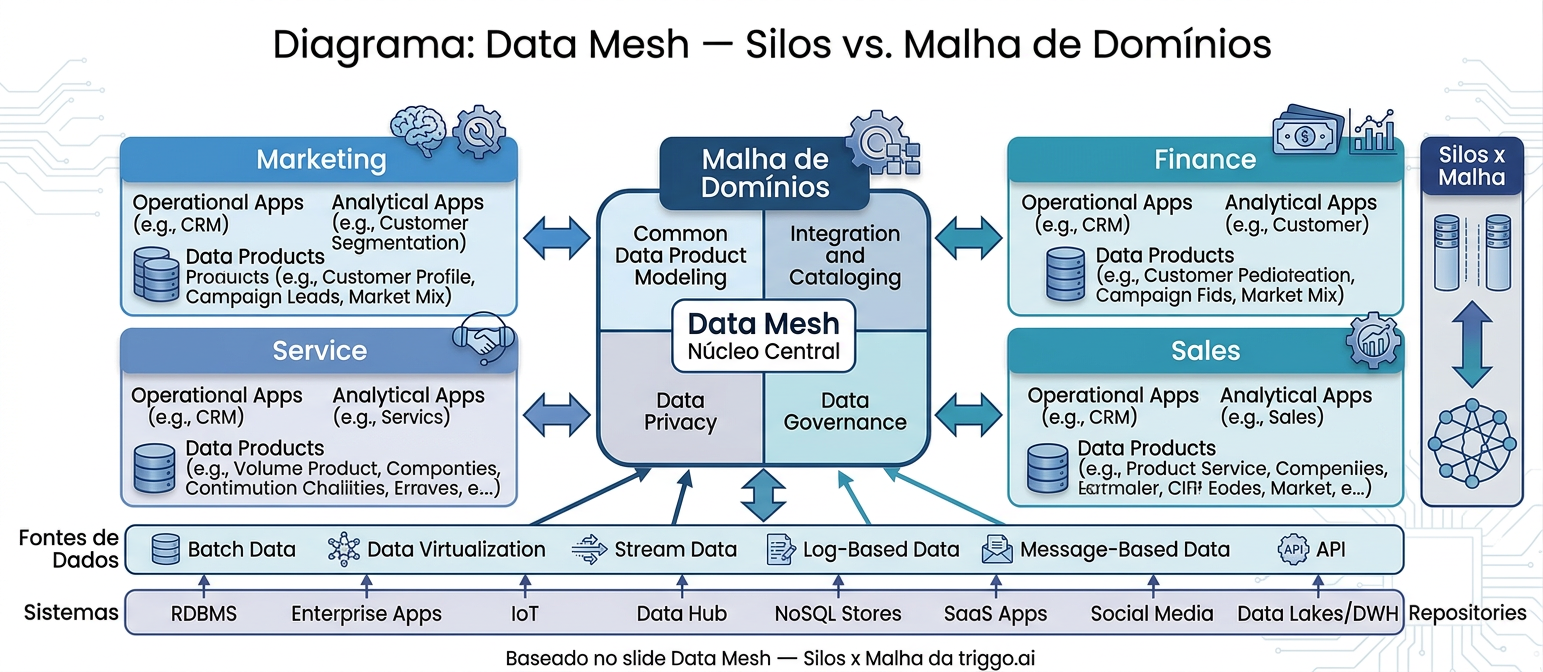
Se o Data Product é a unidade arquitetural, o domínio de dados é a unidade organizacional. Sem entender domínios, a implementação de Data Products fica sem âncora — torna-se apenas uma refatoração técnica sem mudança de accountability.
Um domínio é uma área de conhecimento específica do negócio que tem propriedade sobre os dados que produz e consome. Marketing, Finanças, Crédito, Vendas — cada um desses domínios conhece profundamente os dados que gera em suas operações cotidianas. A lógica do Data Mesh é devolver a responsabilidade pelo dado ao domínio que o gera, em vez de centralizá-la em um time de dados que, por definição, não tem o mesmo contexto de negócio.
"Obter o conhecimento de domínio necessário é uma tarefa difícil. O Central Data Team não consegue conhecer profundamente todos os domínios ao mesmo tempo — e essa é a raiz da maioria dos problemas de qualidade e latência."
— triggo.ai, Aula 2 — Fundamentos sobre Data Product
Domain-Driven Design: a linguagem que conecta técnica e negócio
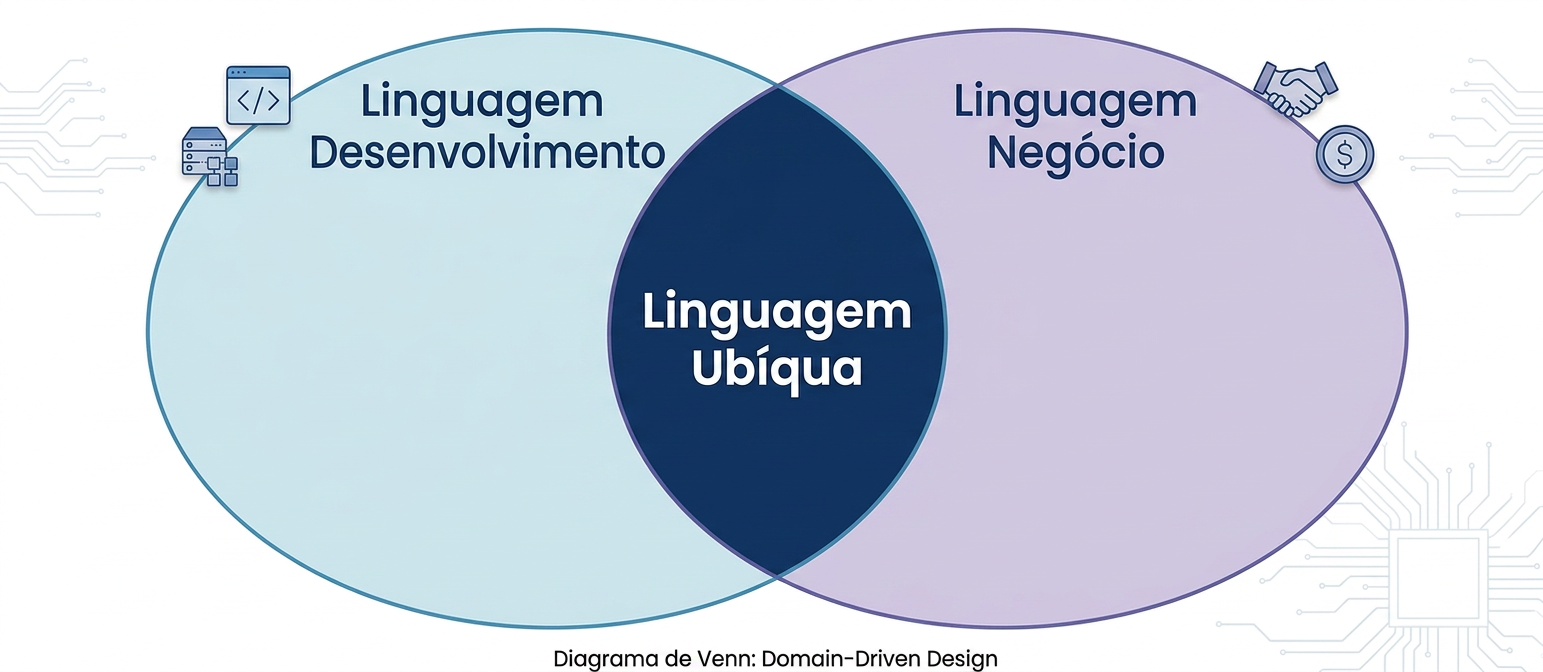
O Domain-Driven Design (DDD), originado na engenharia de software, traz um insight fundamental para dados: a Linguagem Ubíqua — o vocabulário compartilhado que conecta a linguagem técnica do desenvolvimento com a linguagem de negócio do domínio. É a interseção entre o que engenheiros chamam de dado e o que o negócio chama de conceito.
Quando o time de Crédito define "inadimplência" com critérios específicos do negócio, e o time de dados usa uma definição técnica diferente, há uma ruptura semântica que contamina todos os produtos construídos sobre esses dados. O DDD resolve isso criando um modelo compartilhado — e essa é precisamente a fundação de qualquer estratégia de dados semântica bem-sucedida.
Ownership: a principal razão de existir do Data Product
Ownership não é apenas uma questão de responsabilidade técnica — é a principal razão filosófica da existência do conceito de produto de dados. Quando não existe um owner claro de um dado, ninguém é responsável pela sua qualidade, ninguém monitora seu uso, ninguém responde quando ele quebra e ninguém investe na sua evolução.
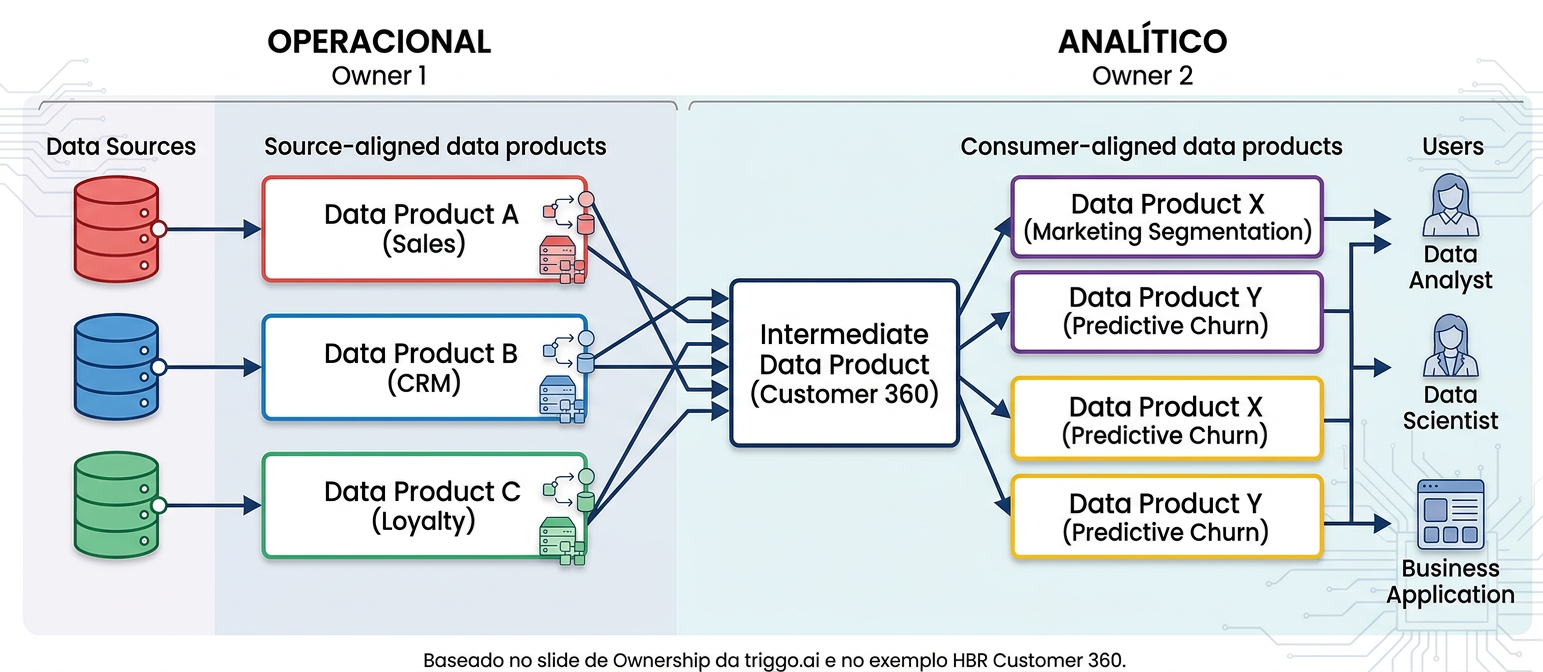
O ownership em um ecossistema de Data Products tem duas dimensões complementares: o owner operacional (responsável pelos dados brutos e pelos sistemas que os produzem — Source-aligned data products) e o owner analítico (responsável pelos produtos construídos sobre esses dados e entregues aos consumidores finais — Consumer-aligned data products). Entre os dois existem os Intermediate data products, que servem como bases reutilizáveis para múltiplos produtos consumidores.
O Product Data Owner — na terminologia da triggo.ai — é alguém que protege o porquê. Não apenas o como técnico, mas o valor de negócio que aquele dado serve, quais decisões ele habilita e como ele evolui com as necessidades da organização.
Exemplo de impacto real — HBR
Um grande banco implementou um produto de dados de visão 360 graus do cliente (Customer 360). Esse único produto habilitou 60 use cases distintos, gerou US$ 60 milhões em receitas incrementais e contribuiu para reduzir US$ 40 milhões em perdas anualmente. A lição: um Data Product bem construído, com domínio claro e alta reutilização, tem impacto financeiro mensurável e sustentável. (Fonte: HBR — A better way to put your data at work)
Os benefícios documentados da abordagem de Data Product
Organizações que adotam o modelo de Data Product de forma consistente reportam três benefícios concretos: novos casos de uso de negócio podem ser entregues até 90% mais rápido quando há produtos reutilizáveis disponíveis; o custo total de propriedade — incluindo tecnologia, desenvolvimento e manutenção — pode diminuir em até 50% com o aumento de reuso e padronização; e a carga de risco e governança de dados pode ser significativamente reduzida quando políticas são embutidas nos produtos, não aplicadas como camadas externas.
Parte II
II
O Playbook: Implementando Data Product com ROI Mensurável
Como transformar o conceito em operação — o ciclo de vida, as métricas de valor e a mudança de mentalidade que separa organizações que falam de Data Products das que colhem resultados reais.
Capítulo 2.1
Por Que as Iniciativas de Dados Falham em Gerar ROI
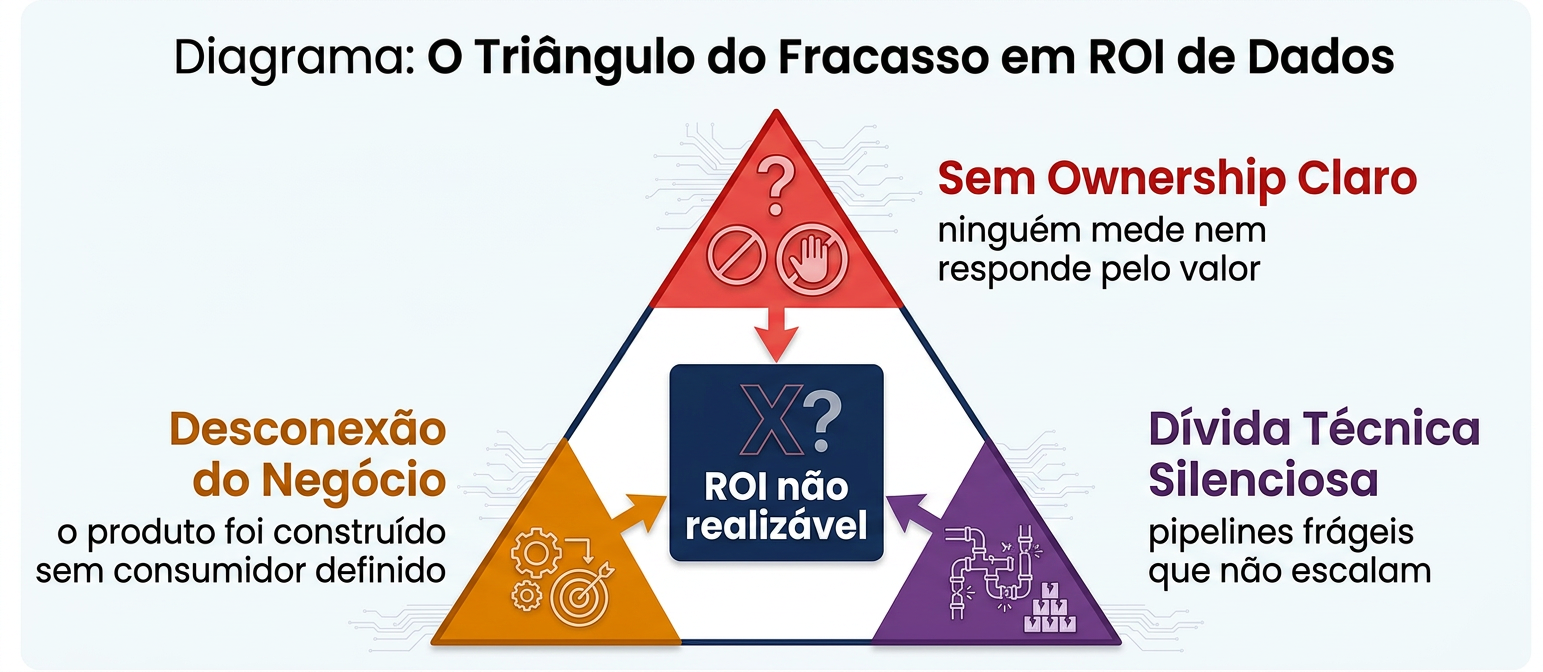
O diagnóstico é mais simples do que parece: a maioria das iniciativas de dados falha não por falta de tecnologia, mas por falta de accountability de valor. A ausência de foco em medição de impacto está estruturalmente embutida na organização de dados tradicional. Engenheiros de dados, arquitetos, DevOps — nenhum desses papéis tem "medir o ROI" como objetivo primário de trabalho.
O segundo problema é de mentalidade: times de dados orientados a projetos focam em escopo, budget e timeline. Entregam o projeto. E pronto. Ninguém se pergunta sistematicamente: esse produto de dados ainda é usado? Está gerando as decisões que deveria? Os melhores projetos de dados, ironicamente, não são liderados pelo time de dados — são liderados por pessoas do negócio com fluência em dados. Marketing otimiza conversão; finanças identifica rentabilidade. O time de dados deveria amplificar, não substituir, esse processo.
O terceiro problema é técnico: produtos criados sem escalabilidade e reutilização em mente se tornam dívida técnica silenciosa. São caros para manter, frágeis quando o dado muda e incapazes de suportar novos casos de uso sem retrabalho extenso. Data Products abandonados são mais comuns do que se imagina — e o Gartner (2024) documenta que apenas 22% das organizações definiram, rastrearam e comunicaram métricas de impacto para a maioria de seus casos de uso de dados e analytics.
Ciclo de vida
Capítulo 2.2
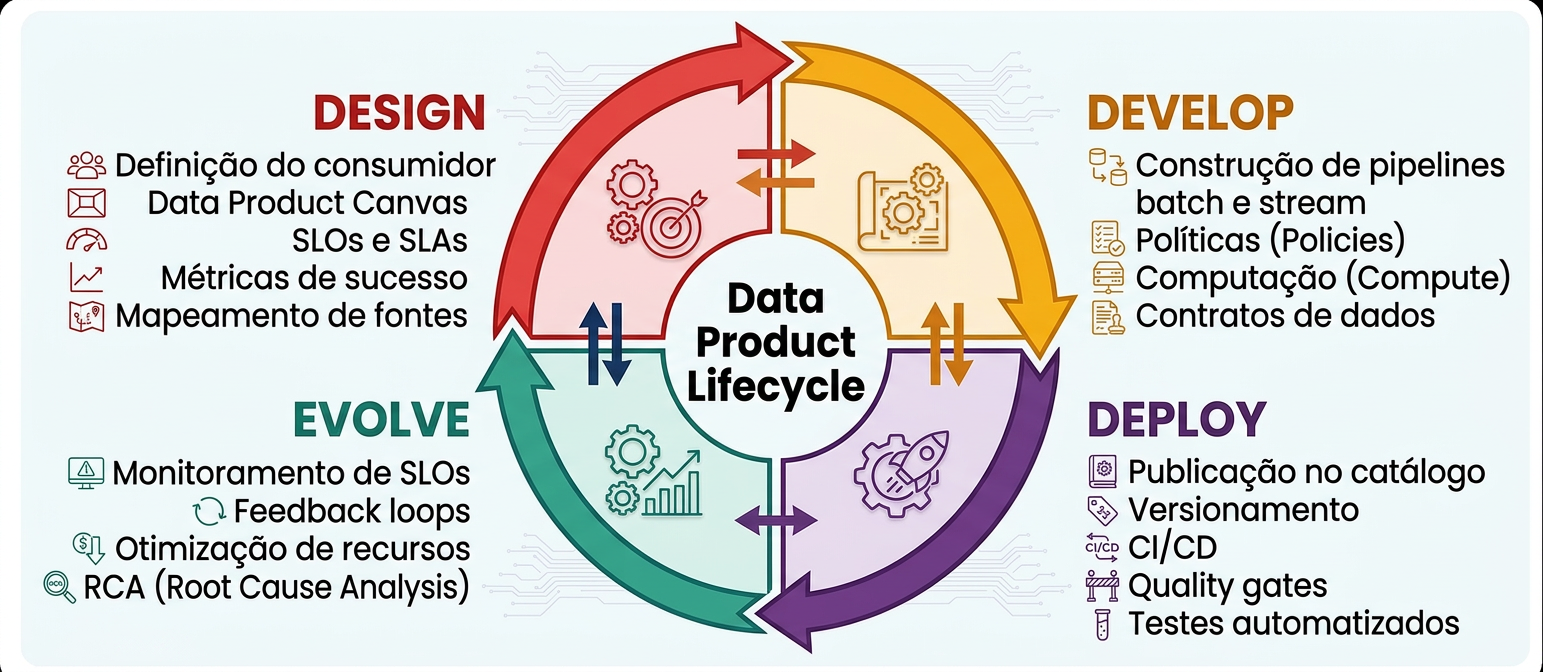
O Ciclo de Vida do Data Product: Design → Develop → Deploy → Evolve
Um produto de dados não tem fim — tem um ciclo. A diferença entre uma iniciativa de dados tradicional e um Data Product está exatamente aqui: o produto nunca está "pronto". Ele é lançado, monitorado, melhorado e eventualmente descontinuado de forma planejada. Esse ciclo contínuo é o que garante relevância e qualidade ao longo do tempo.
Design — Comece pelo consumidor, defina o valor antes do código
A fase de design usa o Data Product Canvas para estruturar: quem consome, qual problema resolve, quais as fontes de ingestão, que transformações são necessárias, quais os SLOs de qualidade e frescor, e quais métricas indicarão sucesso. Nenhuma linha de código deve ser escrita sem essas definições. Os casos de uso são compostos por cinco perguntas essenciais: Qual o problema? Quem é a persona? Por que eles usam isso? Qual é a alternativa? Com que frequência o usam?
Develop — Infraestrutura como habilitador, não como obstáculo
A fase de desenvolvimento constrói pipelines, políticas e interfaces. O ideal é ter todos os recursos necessários — pipelines batch e stream, orquestração, policies, contratos, compute — disponíveis em uma plataforma unificada. A fragmentação de ferramentas aqui é o maior inimigo da produtividade e da consistência. Sprints curtos de 3 dias (em vez dos tradicionais 2 semanas) forçam foco no valor mínimo entregável e feedback rápido dos consumidores.
Deploy — Publicar com contrato, versionar, monitorar desde o dia 1
O deploy vai além de subir código. Inclui publicar no catálogo com metadados completos, versionar a interface de consumo, e garantir que SLOs estejam sendo monitorados desde a primeira execução. CI/CD para dados é tão importante quanto para software — cada mudança de schema ou lógica deve disparar validações automáticas antes de chegar ao consumidor.
Evolve — O loop de melhoria que sustenta o valor no longo prazo
A fase de evolução monitora métricas de negócio, incorpora feedback dos consumidores, otimiza recursos e automatiza manutenção. Ela foca na fitness do produto: monitoramento contínuo através de métricas de negócio, políticas, arquitetura e relacionamentos semânticos. Produtos bem construídos evoluem com baixo custo. Produtos com dívida técnica se tornam bloqueios nessa fase.
Métricas e ROI
Capítulo 2.3
Como Medir o ROI do Data Product
A medição de valor em dados não tem um framework universalmente adotado — mas tem dimensões bem documentadas. As questões-chave que a triggo.ai formula para cada produto em produção são o ponto de partida pragmático: Quanto custa esse Data Product? Qual a sua confiabilidade? Qual o ROI? Quem é o Owner? Qual é o NPS dos consumidores? Qual é o impacto mensurável no negócio?
Dimensão
O que medir
Exemplo de métrica
Confiabilidade
O dado é considerado verdadeiro pelos consumidores?
% de produtos certificados; nº de tickets de verificação; cobertura de linhagem
Acessibilidade
O dado pode ser encontrado e compreendido sem ajuda?
Tempo médio de discovery; % de consumidores self-serve; NPS do produto
Velocidade
Quanto tempo para um novo produto chegar ao mercado?
Lead time de novo Data Product em dias; taxa de reutilização de produtos existentes
Custo
Qual o custo total de propriedade?
Custo de compute + engenharia por produto; custo por consumidor ativo
Impacto no negócio
O produto melhorou KPIs de negócio?
Receita influenciada; custo evitado; melhora em conversão, retenção ou eficiência operacional
Data Contracts: o equivalente das APIs de software
Na engenharia de software, APIs funcionam como contratos entre sistemas — especificando como eles devem se comunicar de forma previsível e segura. Data Contracts são o equivalente para dados: acordos formais entre produtores e consumidores que definem expectativas sobre formato, qualidade e acessibilidade.
Um Data Contract típico especifica: quais colunas existem e seus tipos, taxa de completude mínima por campo, frequência de atualização, SLA de disponibilidade e o que acontece quando há violação. O consumidor do produto de dados pode então confiar que sempre receberá os dados com essas características — e construir suas análises e modelos com base nessa garantia formal, da mesma forma que um desenvolvedor confia em uma API bem documentada.
Gestão do ciclo de vida — visão Gartner
O Gartner formaliza os componentes do Data Product Lifecycle Management em três camadas: Design (integrated databases, pipelines, semantics, metadata, interfaces e templates); Delivery & Provisioning through DataOps (regression test packs, continuous integration, environment configurations, versioning); e Governance (terms and conditions, access controls, pricing, FinOps support, data quality, SLAs). Acima de tudo isso, o Data Contract governa as relações entre produtor e consumidor. No topo, o Data Marketplace expõe os produtos com catálogo publicado, rastreamento via metadata e observabilidade, e conectores para as aplicações consumidoras.
Parte III
III
AI Engineering & Data Product
Como a inteligência artificial transforma a engenharia de dados — automatizando pipelines ETL, acelerando produtividade e redefinindo o que significa construir e operar produtos de dados em escala.
Capítulo 3.1
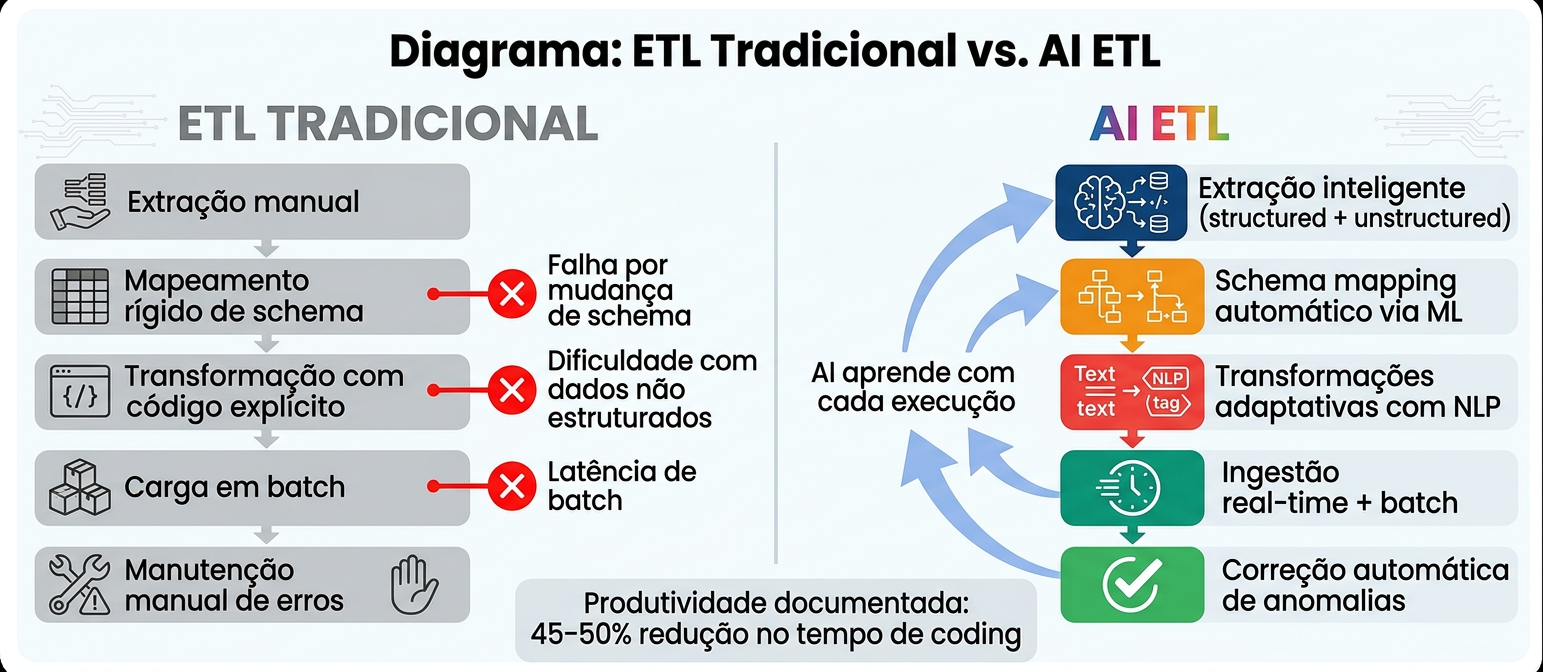
AI ETL: Quando a Inteligência Chega ao Pipeline
Durante décadas, os pipelines ETL (Extract, Transform, Load) foram construídos manualmente. Cada integração exigia código explícito, mapeamentos rígidos de schema e manutenção constante quando os dados mudavam. O custo era alto, a velocidade baixa, e a maior parte do esforço de engenharia ficava presa na plumbing — no trabalho de encanamento que não entrega valor de negócio.
AI ETL representa uma inflexão fundamental nesse paradigma. Plataformas modernas como Databricks e Snowflake incorporam inteligência artificial diretamente na camada de engenharia de dados — não como uma camada separada, mas como parte da infraestrutura de construção e operação dos próprios Data Products. O resultado é um pipeline que aprende, adapta-se e se auto-corrige.
Os limites do ETL tradicional
O ETL tradicional enfrenta três problemas estruturais que se tornaram insustentáveis na escala e na complexidade dos dados modernos. O primeiro é a fragilidade de schema: pipelines dependem de schemas fixos e mapeamentos predefinidos. Quando aplicações introduzem novos campos ou mudam tipos de dados, sistemas rígidos quebram completamente — exigindo dias de engenharia manual para cada variação. Em empresas com dezenas de sistemas de origem, isso cria um custo de manutenção permanente que consome a maior parte da capacidade do time.
O segundo problema é a incapacidade de processar dados não estruturados. A maioria das ferramentas ETL tradicionais se especializa em formatos estruturados de bancos de dados relacionais — mas 80 a 90% dos dados empresariais são não estruturados: documentos, contratos, notas clínicas, e-mails, imagens. Sem capacidade de extração inteligente, organizações movem esses arquivos entre sistemas sem conseguir extrair valor analítico.
O terceiro é a latência do processamento em batch. ETL tradicional opera em lotes, processando dados em intervalos agendados. Isso cria janelas cegas onde eventos críticos ocorrem mas permanecem invisíveis até o próximo ciclo. Para fraud detection, precificação dinâmica ou operações em tempo real, delays de horas tornam os dados inúteis para a decisão que precisava ser tomada.
Como AI transforma cada etapa
Capítulo 3.2
Como AI Powered Platforms Transformam a Engenharia de Dados
Mapeamento inteligente de schema
Plataformas de AI ETL automatizam o mapeamento de schema analisando conteúdo em vez de apenas metadados. Em vez de exigir regras explícitas para cada variação de campo (como "cust_id", "customer_identifier", "client_id"), sistemas de machine learning reconhecem que esses campos representam o mesmo conceito e mapeiam automaticamente — sem intervenção manual.
O processamento de linguagem natural permite que os sistemas entendam significado semântico. Isso é especialmente poderoso no contexto de Data Products: quando um produto de dados define semanticamente o que "cliente" significa no seu domínio, o sistema de AI ETL consegue mapear corretamente dados de qualquer fonte que contenha esse conceito, independentemente do nome técnico da coluna.
Transformação dinâmica e autocorrection
Modelos de ML aprendem com transformações bem-sucedidas anteriores e aplicam padrões similares a novos dados automaticamente. Quando mudanças de schema ocorrem — um novo campo adicionado, um tipo alterado —, o sistema detecta a variação e adapta sem parar o pipeline. Isso transforma o pipeline de um sistema frágil que quebra com mudanças para um sistema resiliente que evolui com os dados.
AI driven transformation estende-se também à qualidade: modelos aprendem os padrões típicos de dados válidos — formatos corretos de telefone, intervalos monetários realistas, relacionamentos esperados entre campos. Quando anomalias surgem, sistemas aplicam correções automaticamente e registram o evento para auditoria, mantendo os SLOs do produto sem intervenção humana.
Processamento de dados não estruturados
Uma das mudanças mais significativas do AI ETL é a capacidade de processar dados não estruturados a escala. Plataformas como Databricks com sua feature ai_parse e equivalentes do Snowflake permitem que documentos, PDFs, e-mails e imagens sejam processados declarativamente — sem pipelines OCR customizados ou scripts complexos de extração.
Isso abre uma nova categoria de Data Products: produtos baseados em dados que antes eram inacessíveis ao analytics. Notas clínicas processadas em tempo real. Contratos indexados semanticamente. Transcrições de chamadas transformadas em métricas de experiência. A fronteira entre "dado estruturado" e "dado não estruturado" dissolve-se progressivamente.
Caso real — Banco Bradesco com Databricks Assistant
O time de engenharia de dados do Banco Bradesco adotou assistência GenAI no desenvolvimento de pipelines. Resultado: redução de 50% no tempo de coding e capacidade para que usuários técnicos e não-técnicos gerassem e depurassem código usando linguagem natural — democratizando o acesso à engenharia de dados e reduzindo o gargalo de skills especializadas.
Text-to-SQL e capacidade agentica
Capítulo 3.3
Text-to-SQL: Democratizando o Acesso ao Dado
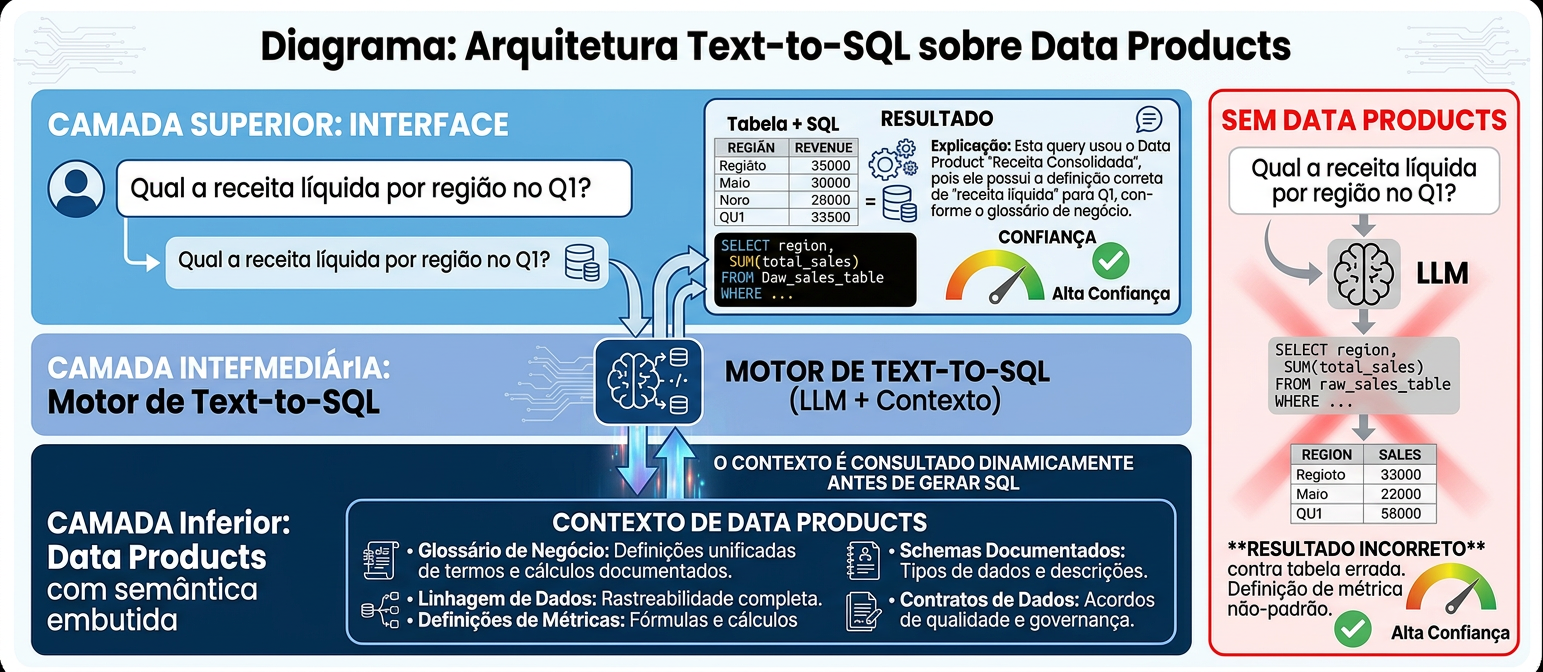
O Text-to-SQL é provavelmente a aplicação de AI na engenharia de dados com maior impacto imediato para os consumidores de dados. A ideia é simples: o usuário descreve em linguagem natural o que precisa saber, e o sistema gera a query SQL correspondente. O que estava reservado a analistas com fluência em SQL passa a ser acessível a qualquer profissional com conhecimento de negócio.
Na prática, porém, Text-to-SQL sem contexto semântico é instável. O modelo pode gerar SQL sintaticamente correto mas semanticamente errado — referenciando a tabela errada, usando a definição incorreta de uma métrica, ou ignorando exceções específicas do domínio. Uma query que parece correta pode retornar números errados com alta confiança.
É aqui que o Data Product se torna habilitador crítico: quando o dado tem semântica documentada, contratos explícitos e metadados ricos, o modelo de linguagem tem o contexto necessário para gerar queries corretas e confiáveis. O Data Product não é apenas o dado — é o contexto que torna o dado inteligível para sistemas automatizados.
Arquiteturas agentias para análise de dados moderna
O passo além do Text-to-SQL é a análise agentica: sistemas que não apenas geram uma query, mas orquestram múltiplas etapas de raciocínio para responder perguntas complexas de negócio. Um agente analítico moderno pode, de forma autônoma: identificar quais Data Products são relevantes para uma pergunta; consultar contratos e metadados para entender semântica e linhagem; escrever e executar queries; interpretar os resultados em contexto de negócio; e propor hipóteses adicionais de investigação — tudo sem intervenção humana.
Existem dois padrões arquiteturais dominantes. O fluxo declarativo tem um caminho predefinido — o agente segue uma sequência de ferramentas para chegar ao resultado. É mais previsível e auditável. O fluxo ReAct (Reasoning + Action) é iterativo — o agente decide a cada passo qual ferramenta usar baseado no contexto acumulado, adaptando-se conforme os resultados intermediários chegam. É mais flexível para perguntas abertas.
Ambos os padrões dependem criticamente de uma coisa: a qualidade do contexto disponível. E é por isso que Data Products não são apenas úteis na era agentica — eles são a pré-condição para que essa arquitetura funcione com confiabilidade em produção.
Impacto de produtividade: o que os dados dizem
41%
dos times de dados com GenAI reportam 15–30% de ganho de produtividade na entrega geral (Prophecy, 2025)
50%
de redução no tempo de coding reportada pelo Banco Bradesco com Databricks Assistant
80%+
de redução de esforço manual na documentação automática de metadados e linhagem
Tarefa no Pipeline de Dados
Como a AI acelera
Ganho estimado
Geração de código SQL e Python
LLMs geram transformações a partir de prompts em linguagem natural, reduzindo dias para minutos
45–50% menos tempo de coding
Documentação de dados
Geração automática de descrições, metadados e lineage a partir do código existente
80%+ de redução de esforço manual
Schema mapping e integração
ML mapeia campos semanticamente equivalentes sem regras explícitas por variação
Eliminação de dias de mapeamento manual
Testes e validação de qualidade
Agentes geram casos de teste e validam schema automaticamente em cada mudança
Redução de ciclos de QA
Debugging e análise de causa raiz
Análise automática de logs e sugestão de causa raiz para falhas de pipeline
30–40% menos tempo de diagnóstico
Migração de ETL legado
Agentes convertem pipelines em dialetos antigos para plataformas modernas
Compressão de meses para semanas
Perspectiva triggo.ai — Lições Aprendidas
Na prática com clientes, os maiores ganhos de AI Engineering acontecem quando há uma base de Data Products bem definida. A AI amplifica o que já é bom — não conserta o que está quebrado. Um pipeline frágil com documentação pobre gera prompts ruins e outputs instáveis. Um Data Product com contrato, semântica e linhagem claros gera contexto rico que o LLM pode usar para produzir código confiável.
A recomendação: invista primeiro na fundação (domínios, ownership, contratos de dados), e então introduza AI como acelerador da esteira de produto. Não o contrário.
Parte IV
IV
Data Product na Era da IA Generativa
Como agentes de IA, LLMs e a nova arquitetura de contexto tornam o Data Product indispensável — e por que a convergência entre Agentic AI, MCP e Data Products abre uma nova fronteira para as organizações orientadas a dados.
Capítulo 4.1
O Ano em que os Agentes de IA Falharam — e a Lição que Ficou
Entre 2024 e 2025, "agentes de IA para seus dados" foi uma das categorias mais promovidas no software empresarial. A promessa era sedutora: pergunte seus dados em inglês, receba a resposta. Pule o analista, pule o dashboard, pule o SQL. E ao longo desse período, a maioria desses agentes falhou em produção.
O problema não era o modelo de linguagem. Os modelos melhoraram dramaticamente — janelas de contexto maiores, raciocínio mais sofisticado. O problema persiste mesmo com modelos melhores porque está numa camada anterior: o contexto. Um analista humano que acessa o data warehouse não vê apenas tabelas. Ele sabe qual tabela é a "real". Sabe que "receita" significa líquida de devoluções. Sabe que o trimestre fiscal termina no dia 28. A maior parte do que torna o warehouse útil para um analista é o contexto acumulado na cabeça do analista — não nos dados em si.
Um agente de IA que acessa o mesmo warehouse tem acesso às tabelas, mas não ao contexto. Quando perguntado "qual foi o crescimento de receita no último trimestre?", o agente escreve SQL competente contra uma tabela plausível e retorna números errados com alta confiança. O modelo não era o gargalo. O modelo estava voando às cegas num ambiente que dependia de contexto que ele não tinha.
A conclusão que se solidificou é que contexto precisa se tornar uma camada arquitetural de primeira classe — não um prompt, não um wiki, não conhecimento tribal que evapora quando alguém sai do time. E a forma correta que essa camada deve tomar já existe com um nome conhecido: o Data Product. Um Data Product bem construído é, essencialmente, contexto empacotado como um ativo de primeira classe.
Design agentico e Data Products
Capítulo 4.2
DATA & AI Design: Arquitetando a partir dos Agentes de IA
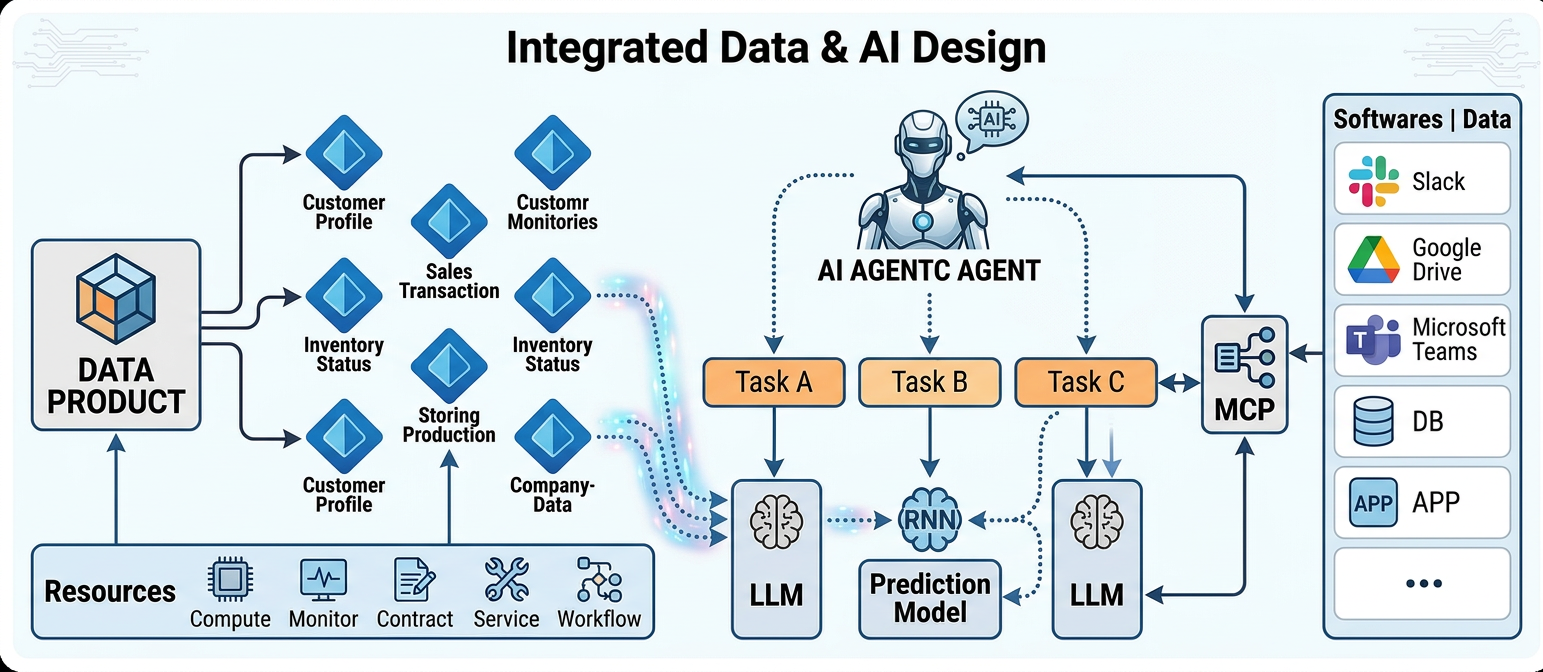
A triggo.ai propõe uma nova perspectiva de design de sistemas de dados que parte de uma premissa invertida: em vez de construir Data Products e depois pensar em como conectá-los à IA, a organização deve projetar seus Data Products desde o início para serem consumidos por agentes de IA — com todos os recursos, contratos e semântica necessários embutidos na arquitetura do produto.
Nessa visão, um agente de IA agentico opera sobre uma arquitetura em camadas: na base, os Data Products com seus recursos fundamentais (Compute, Monitor, Contract, Service, Workflow); acima, os produtos compostos de domínio que servem aos agentes; no topo, o agente orquestra múltiplas Tasks (A, B, C) cada uma resolvida por modelos específicos (LLM, Prediction Model, RNN) conforme a natureza do problema. A lateral conecta o agente a todos os softwares e sistemas da organização via protocolo MCP (Model Context Protocol).
Essa arquitetura tem uma implicação prática poderosa: um agente bem projetado não precisa de um Data Product monolítico que antecipa todas as possíveis perguntas. Ele precisa de Data Products modulares, com semântica rica, que podem ser compostos dinamicamente conforme a intenção do usuário. A capacidade do agente de sintetizar informação de múltiplos domínios em tempo real é o que torna os "Produtos de Dados Dinâmicos" possíveis.
Cross Domain AI Agentic Pattern
Capítulo 4.3
Cross Domain AI Agentic Pattern: Síntese Dinâmica entre Domínios
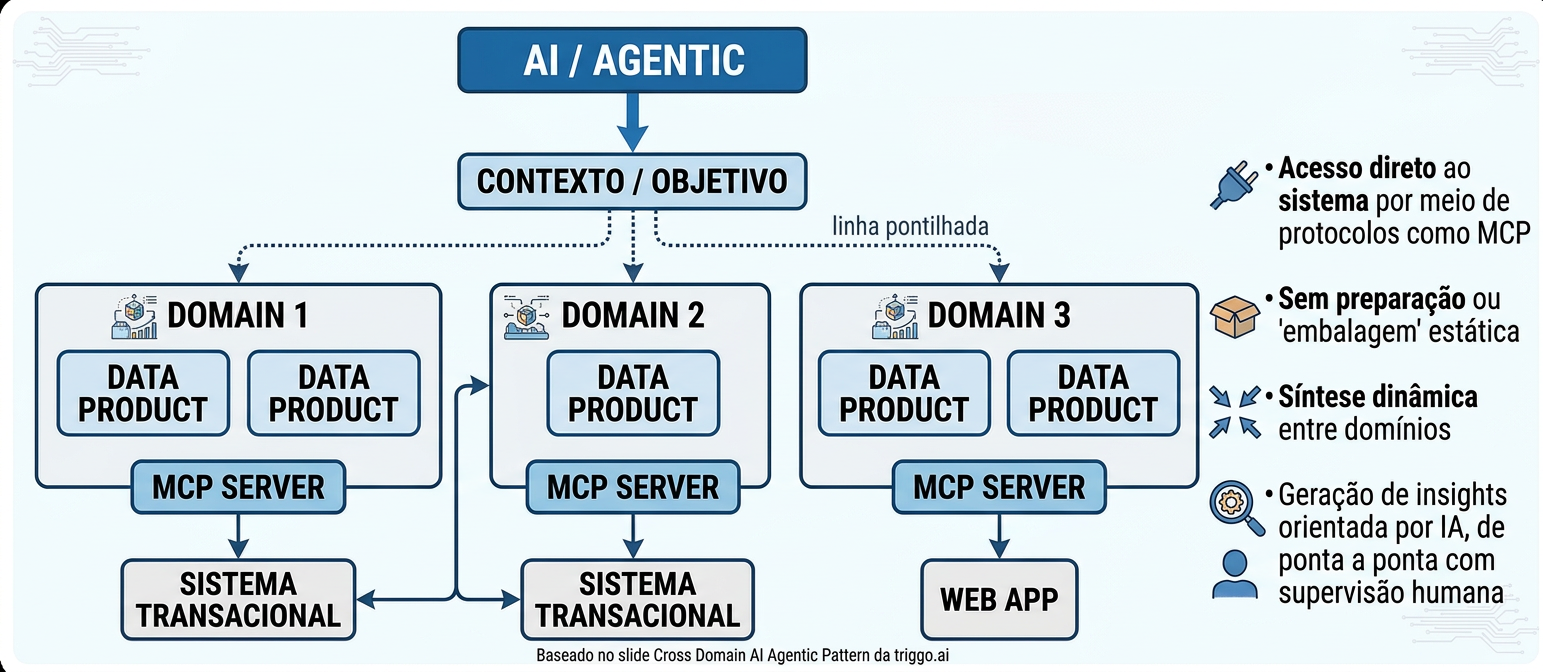
O padrão mais sofisticado de uso de agentes de IA com Data Products é o Cross Domain AI Agentic Pattern — onde um único agente sintetiza informações de múltiplos domínios de dados para gerar insights que nenhum domínio isolado poderia produzir.
O fluxo funciona assim: um agente recebe um Contexto/Objetivo (por exemplo, "identificar os principais fatores de churn entre clientes premium no último trimestre"). Para responder, ele não acessa um único Data Product — ele navega por múltiplos domínios (Crédito com seus Data Products de risco, Produto com seus Data Products de uso, Marketing com seus Data Products de campanha), e para cada domínio usa o MCP Server correspondente para acessar sistemas transacionais ou aplicações web específicas.
As quatro características que definem esse padrão são fundamentais para entender sua diferença em relação a abordagens tradicionais de analytics. O acesso via protocolo MCP permite que o agente alcance sistemas transacionais em tempo real, sem depender de ETL prévio. A ausência de "embalagem" estática significa que os dados não precisam ser preparados antecipadamente para cada possível pergunta. A síntese dinâmica entre domínios cria insights cruzados que seriam impossíveis para qualquer analista humano processar manualmente na mesma velocidade. E a supervisão humana end-to-end garante que a geração de insights permanece auditável e governada.
Produtos de Dados Dinâmicos: a próxima fronteira
O conceito de Produtos de Dados Dinâmicos representa a evolução natural dessa arquitetura. No futuro próximo, a dependência de equipes de domínio para empacotar e preparar dados estaticamente para cada parte de cada pergunta será significativamente reduzida. Em vez de Data Products pré-construídos para casos de uso específicos, os agentes de IA serão capazes de compor dados dinamicamente a partir de produtos modulares — como blocos de LEGO semânticos que se combinam conforme a intenção do usuário.
Isso não elimina os Data Products — pelo contrário, os torna mais importantes. A diferença é que em vez de cada produto precisar antecipar todos os usos possíveis, cada produto precisa ter semântica, linhagem, qualidade e governança suficientemente ricos para ser combinado de forma confiável com outros produtos em tempo de execução.
"No futuro breve, reduziremos a dependência de equipes de domínio para empacotar e preparar dados estaticamente para cada parte de cada pergunta."
— triggo.ai — Produtos de Dados Dinâmicos
Governança para IA
Capítulo 4.4
Dados Seguros para Agentes: Governança que Acompanha a Velocidade da IA
A adoção de agentes de IA em produção coloca desafios de governança que arquiteturas de dados tradicionais não foram projetadas para resolver. Quando um agente pode autonomamente descobrir, combinar e consultar dados de múltiplos domínios via MCP, o perímetro de risco se expande de forma não linear. Quatro problemas críticos emergem:
🔍
Ambiguidade Semântica
Agentes inferem significado sem definições explícitas, produzindo resultados errados com alta confiança. Solução: semântica embutida no produto, não anotada depois.
🧩
Contexto Fragmentado
Definições, linhagem e políticas em sistemas separados criam inconsistência. Agentes precisam de um ponto único de contexto confiável por produto.
⚡
Fragilidade de Interface
Agentes que dependem de schemas voláteis quebram quando tabelas mudam. Interfaces estáveis via Data Product API são muito mais resilientes e previsíveis.
🛡️
Governança Reativa
Políticas de PII e compliance aplicadas após a produção chegam tarde. Políticas embutidas no produto garantem conformidade contínua sem overhead manual.
Perspectiva triggo.ai — Governança como Código
Em projetos com clientes de setores regulados (financeiro, saúde), a triggo.ai observa que a governança de dados para IA precisa ser tratada como código: versionada, testada automaticamente e embutida no pipeline de entrega do Data Product — não documentada apenas em um manual de políticas.
Quando um agente acessa um produto de dados, as garantias de governança já estão lá. Não precisam ser verificadas separadamente. Esse é o princípio do "compliance by construction" — e é o que permite que organizações escalem o uso de agentes sem escalar proporcionalmente o risco de compliance.
Parte V
V
Passo a Passo: De Data Management a Data Product
O guia prático e completo para transformar a operação de dados da sua organização — e por que essa jornada é, antes de tudo, uma mudança de identidade do time de dados.
Capítulo 5.1
Uma Mudança de Identidade: O Que Está Realmente em Jogo
A transição de Data Management orientado a projetos para uma organização orientada a Data Products não é, fundamentalmente, uma mudança técnica. É uma mudança de identidade do time de dados. E como toda mudança de identidade profunda, ela vai além de ferramentas, processos ou metodologias — ela redefine o que significa ser um profissional de dados, o que o time entrega, para quem entrega e como mede o próprio sucesso.
No modelo de projeto, o time de dados é um fornecedor de serviços especializado. Ele recebe demandas, estima esforço, entrega relatórios, dashboards e pipelines. Sua identidade é técnica: domínio de SQL, Python, Spark, ferramentas de BI. O sucesso é medido por entrega no prazo, dentro do budget. O relacionamento com o negócio é transacional — existe enquanto o projeto existe.
No modelo de produto, o time de dados é um construtor de ativos estratégicos. Ele identifica problemas de negócio não resolvidos, define produtos que entregam valor contínuo, mede o impacto das decisões que habilita. Sua identidade é híbrida: técnica e de negócio simultaneamente. O sucesso é medido pelo valor gerado — receita influenciada, custo evitado, velocidade de decisão. O relacionamento com o negócio é de parceria duradoura — existe enquanto o produto existe.
"O time de dados deixa de ser fornecedor de serviços e passa a ser construtor de produtos estratégicos. Essa inversão de identidade é a mudança mais difícil — e a mais transformadora."
— triggo.ai · Data & AI Product Management
A escala de maturidade: de processo a valor
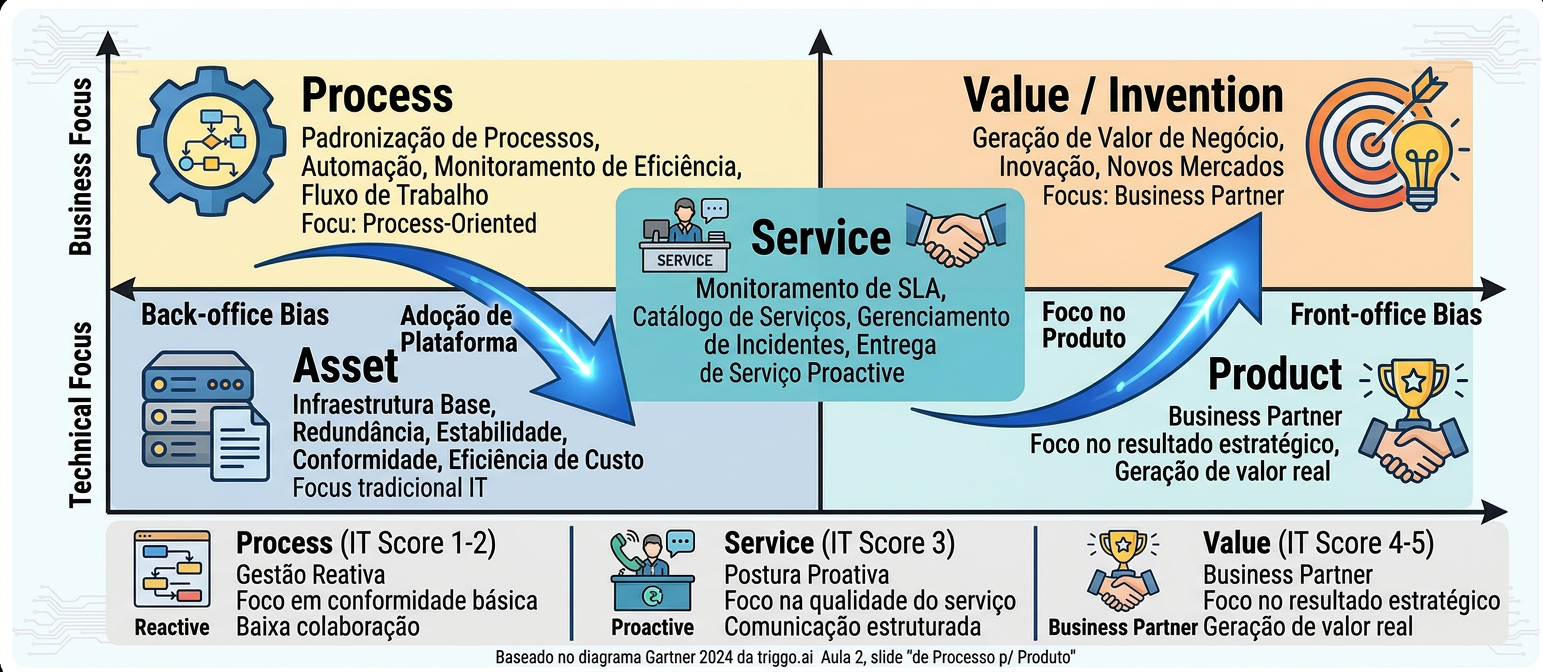
O Gartner (2024) mapeou claramente a trajetória que as organizações de TI e dados precisam percorrer: de um modelo orientado a Processo (IT Score Nível 1 e 2, foco em "rodar o negócio") passando por Serviço (Nível 3, provedor proativo) até chegar ao nível de Valor (Níveis 4 e 5, parceiro de negócio com foco em crescer e transformar). A maioria das organizações ainda está presa nos níveis 1 e 2 — com dados tratados como ativo estático e equipes que reagem a chamados.
O que muda concretamente para cada papel
A mudança de identidade não acontece em abstrato — ela se manifesta em comportamentos, responsabilidades e métricas concretas para cada papel no time de dados:
Papel
Identidade no modelo de projeto
Identidade no modelo de produto
Engenheiro de Dados
Constrói pipelines por demanda; entrega conforme spec
É guardião da qualidade do produto; define SLOs e responde por eles
Analista de Dados
Responde perguntas; produz relatórios ad hoc
Identifica oportunidades de produto; mede impacto das decisões habilitadas
Data Product Manager
(papel raramente existente)
Define a visão e prioridade do produto; conecta negócio e técnica; mede ROI
Arquiteto de Dados
Define schemas e modelos de dados
Define padrões de produto, contratos de dados e governança federada
Líder de Dados (CDO)
Gerencia projetos e recursos
Gerencia portfólio de produtos; comunica valor ao board; define estratégia de domínios
Essa transição de identidade é, via de regra, a parte mais difícil da jornada de Data Product. Não porque as pessoas não queiram mudar — mas porque as estruturas de incentivo, as métricas de performance, as ferramentas e os rituais organizacionais foram todos construídos para o modelo antigo. Mudar a identidade exige mudar tudo isso simultaneamente, de forma coordenada.
O roadmap de implementação
Capítulo 5.2
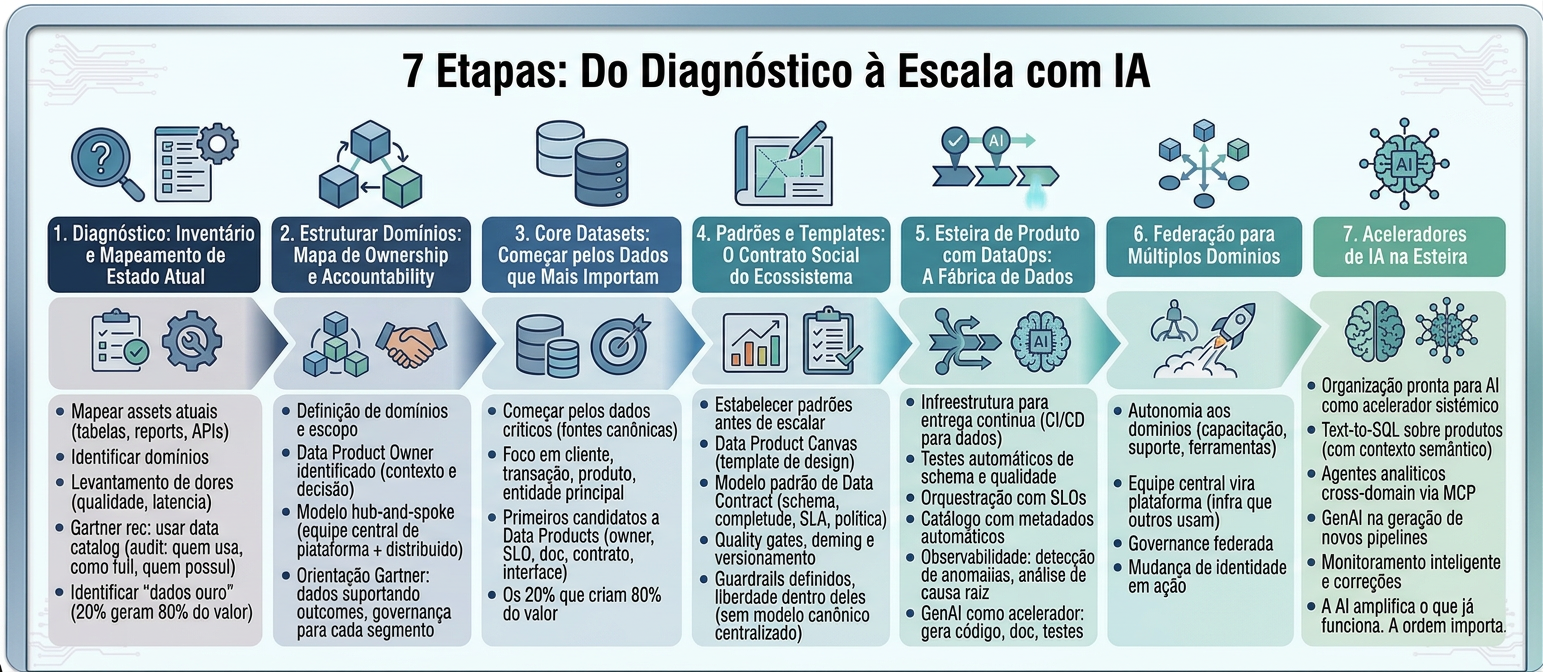
O Roadmap em 7 Etapas: Do Diagnóstico à Escala com IA
Diagnóstico: Inventário e Mapeamento do Estado Atual
Antes de construir qualquer coisa, mapeie o que existe. Inventário de assets atuais (tabelas, reports, modelos, APIs), identificação dos domínios de negócio, levantamento de dores de qualidade e latência. O Gartner recomenda o enterprise data catalog como ferramenta prática desse audit — ele revela quais assets existem, quem os usa, como fluem e quem os possui. Identifique os "dados ouro": os 20% dos dados que geram 80% do valor decisório da organização. Esses são os primeiros candidatos a produtos.
Estruturar Domínios: Mapa de Ownership e Accountability
Com o inventário em mãos, defina os domínios de negócio e seu escopo de responsabilidade. Cada domínio precisa de um Data Product Owner identificado — alguém com contexto de negócio e capacidade de tomar decisões sobre qualidade e prioridade. O modelo hub-and-spoke funciona bem: uma equipe central de plataforma que define padrões, com ownership distribuído aos domínios. O Gartner orienta: identifique os dados que suportam cada outcome de negócio e desenvolva ownership e governança para cada segmento.
Core Datasets: Começar pelos Dados que Mais Importam
Não tente transformar tudo de uma vez. Comece pelos Core Datasets — as fontes canônicas que servem a maior parte dos casos de uso críticos. Na prática, esses costumam ser os dados de cliente, transação, produto e entidade principal do negócio. Defina esses datasets como os primeiros candidatos a se tornarem Data Products com todos os atributos: owner, SLO, documentação, contrato e interface estável. Os 20% dos dados que criam 80% do valor.
Padrões e Templates: O Contrato Social do Ecossistema
Antes de escalar, estabeleça os padrões que todos os produtos seguirão: Data Product Canvas como template de design, modelo padrão de Data Contract (schema, completude mínima, SLA de frescor, política de acesso), critérios de quality gate para publicação no catálogo, e padrões de naming e versionamento. Esses padrões são o "contrato social" que permite escalar sem perder consistência. Não construa um modelo canônico centralizado — defina apenas os guardrails, deixando os domínios com liberdade dentro deles.
Esteira de Produto com DataOps: A Fábrica de Dados
Com os primeiros produtos definidos e padrões estabelecidos, construa a infraestrutura que viabiliza entrega contínua. Isso inclui CI/CD para dados (testes automáticos de schema e qualidade a cada mudança), orquestração de pipelines com monitoramento de SLOs, catálogo com metadados publicados automaticamente, e observabilidade: detecção proativa de anomalias e análise de causa raiz. Aqui a GenAI entra como acelerador: ferramentas que geram código de transformação, documentação e testes a partir de prompts reduzem significativamente o onboarding de novos produtos.
Federação para Múltiplos Domínios
Com a plataforma funcional e os padrões provados no piloto, a jornada de federação começa. Cada domínio recebe capacitação, suporte e ferramentas para construir e operar seus produtos com autonomia. A equipe central de dados deixa de ser entregadora e passa a ser plataforma — seu produto é a infraestrutura que outros times usam. Governance federada: cada domínio tem liberdade dentro dos guardrails centrais. Essa inversão de papel é, novamente, a mudança de identidade em ação.
Aceleradores de IA na Esteira
Com base sólida de Data Products em produção, a organização está pronta para AI como acelerador sistêmico: Text-to-SQL sobre produtos no catálogo (com contexto semântico disponível para o LLM), agentes analíticos cross-domain via MCP, GenAI na geração de novos pipelines, e monitoramento inteligente que detecta anomalias e sugere correções. A ordem importa: a AI amplifica o que já funciona. Uma fundação ruim de dados não é resolvida com IA — é amplificada em escala.
Conclusão
O Futuro é Agora — e Começa com uma Decisão de Identidade
A jornada descrita neste book não é linear nem rápida. É uma transformação que começa com uma decisão de identidade — o time de dados decide que não quer mais ser fornecedor de serviços, e passa a querer ser construtor de produtos. Essa decisão precede qualquer escolha técnica, qualquer implementação de plataforma, qualquer definição de processo.
O momento para começar nunca foi melhor. A pressão da IA Generativa criou um senso de urgência que coloca o CDO no centro da estratégia de negócio. Executivos que nunca se importaram com Data Contracts agora se importam porque entendem que agentes de IA sem contexto confiável são agentes que tomam decisões erradas com confiança. A janela está aberta.
Recomendações Finais triggo.ai
Comece pelos Core Datasets. Não transforme tudo ao mesmo tempo. Os 20% dos dados que geram 80% do valor merecem atenção de produto de alta qualidade primeiro.
Defina ownership antes de construir tecnologia. Sem ownership claro, tudo que você construir ficará sem manutenção. O owner protege o porquê — e sem porquê, não há produto, há artefato.
Trate a mudança de identidade como o projeto mais importante. As resistências à adoção de Data Products raramente são técnicas — são culturais. Invista tanto na mudança de mentalidade quanto na mudança de arquitetura.
Use IA para acelerar, não para atalhar. GenAI na esteira de dados é um multiplicador de produtividade — mas só funciona sobre uma base sólida de dados com contexto semântico.
Meça o ROI desde o primeiro produto. Um produto sem baseline de impacto é um projeto com outro nome. Estabeleça as métricas antes de lançar.
"O futuro pertence às organizações que constroem fundações de dados que humanos e agentes de IA possam confiar igualmente — e aos times de dados que se identificam como construtores de valor, não entregadores de serviço."
— triggo.ai · Data & AI Product Management
By continuing to use our site, you acknowledge the use of cookies to improve your experience, analyze traffic, and personalize content. Read our Privacy Policy.